一开始本文叫做“聊聊大模型推理中的存储优化”的,但是发布之后感觉还是要叫分离式推理更好,虽然我本来是想写存储优化的,存储优化太大了,还是聚焦一下。
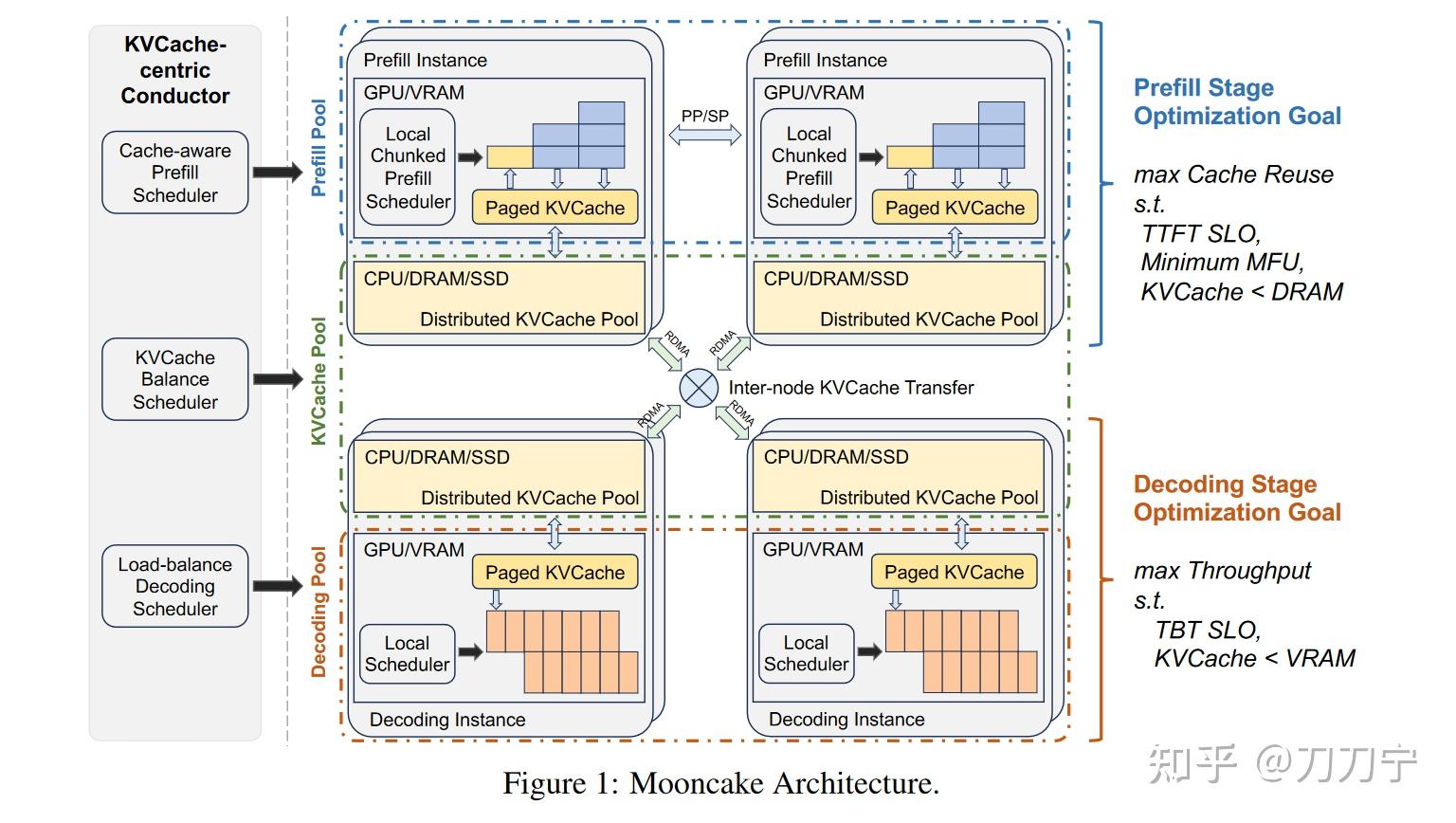
<hr/>存储优化是大模型推理中非常重要的一个环节。我在 聊聊大模型推理服务中的优化问题 中对一部分论文进行了解读,主要包括 Efficient Memory Management for Large Language Model Serving with PagedAttention(也就是vllm)等方法,最近正好和几篇热点论文再拓展阅读一下,例如月之暗面 KIMI chat 的 Mooncake 。
存储管理,包括计算芯片缓存、显存、内存甚至磁盘,都可以算在内,因为不管是对离线的参数、缓存,还是对在线的数据搬运、数据复用,都属于存储管理。这篇笔记会更加侧重于如何优化当前大模型自回归特点下的 KVCache 在内存和显存中的摆放位置、管理、检索、传输、预测等等,目标则是为了从整体上提高服务的服务质量,减小延时,提高吞吐。
<hr/>1、近期的三篇推理技术综述:Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems、LLM Inference Unveiled: Survey and Roofline Model Insights 和 A Survey on Efficient Inference for Large Language Models 等中都专门留了章节给这部分内容。
2、vAttention (微软印度搞的)是认为 vLLM 的 PagedAttention 需要重写注意力核来支持分页增加了软件复杂性,所以就提出了保留连续的虚拟内存,利用系统已有的按需分页支持来实现物理内存的按需分配,进而动态的管理 KVCache 内存的方法。实验结论是其比 vLLM 快 1.97 倍,单 prefill 阶段比 FlashAttention 快 3.92 倍,比 FlashInfer 1.45 倍。这方法是在底层优化 pagedAttention 相关技术的,其立意和实现都比较底层,但是没有开源。这里有一篇写的很详细的解读:BBuf:vAttention:用于在没有Paged Attention的情况下Serving LLM

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2024-10-10 16:41
发表于 2024-10-10 16:41


 提升卡
提升卡


