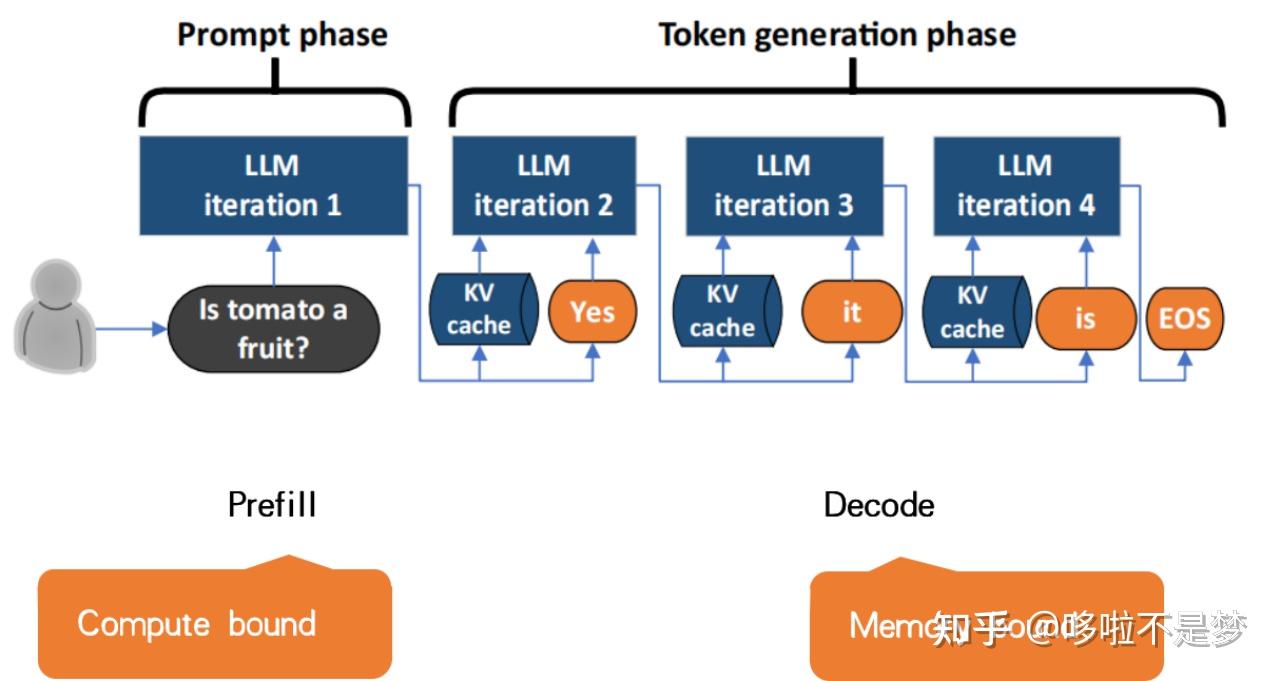
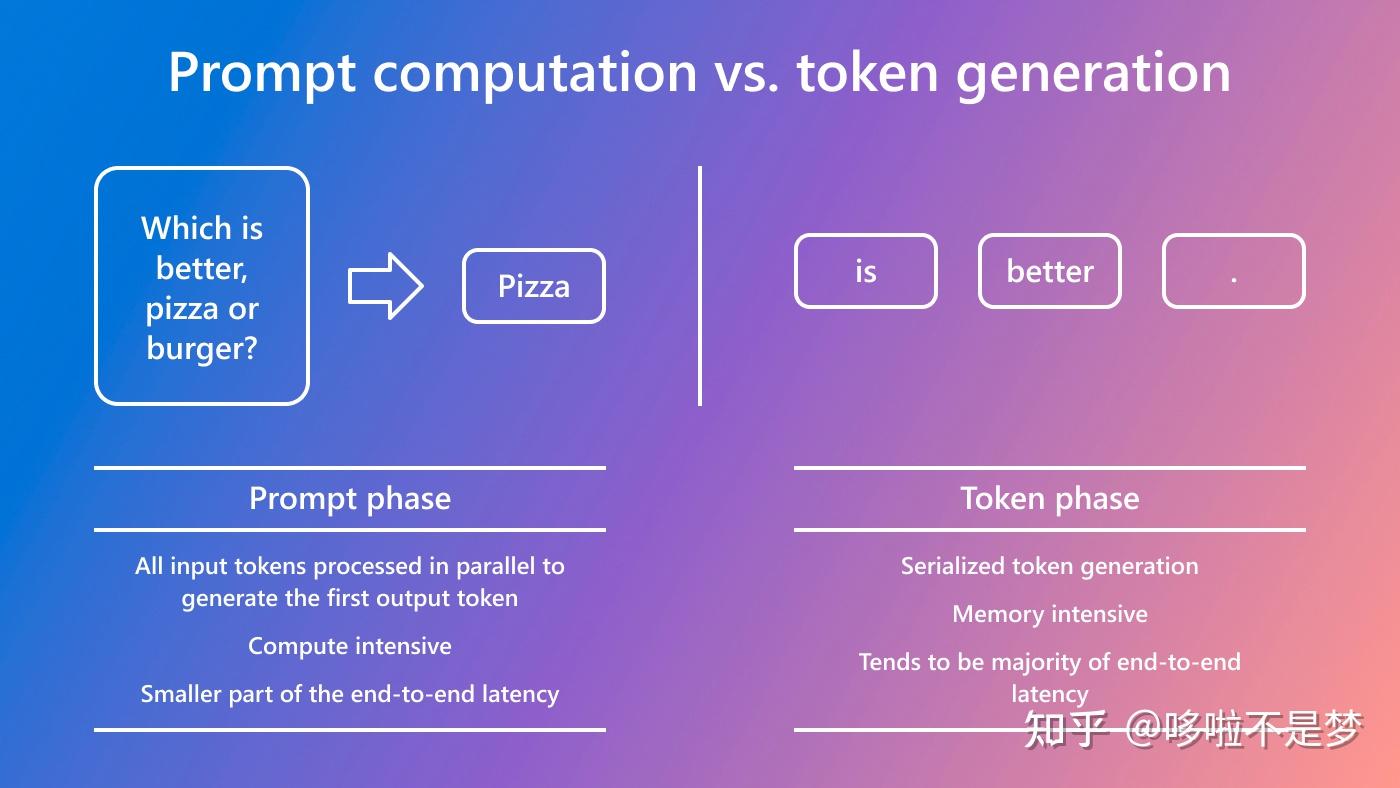
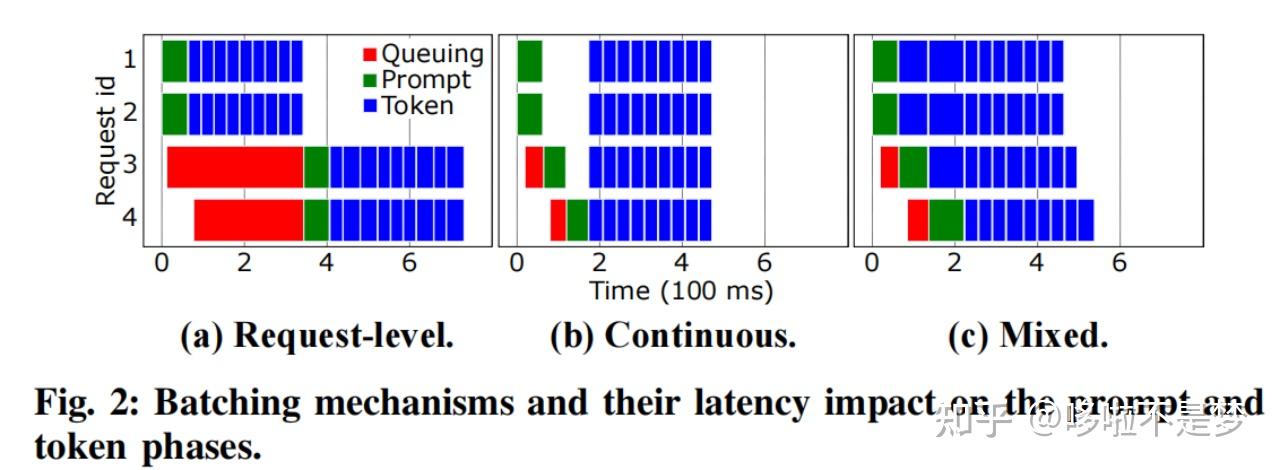
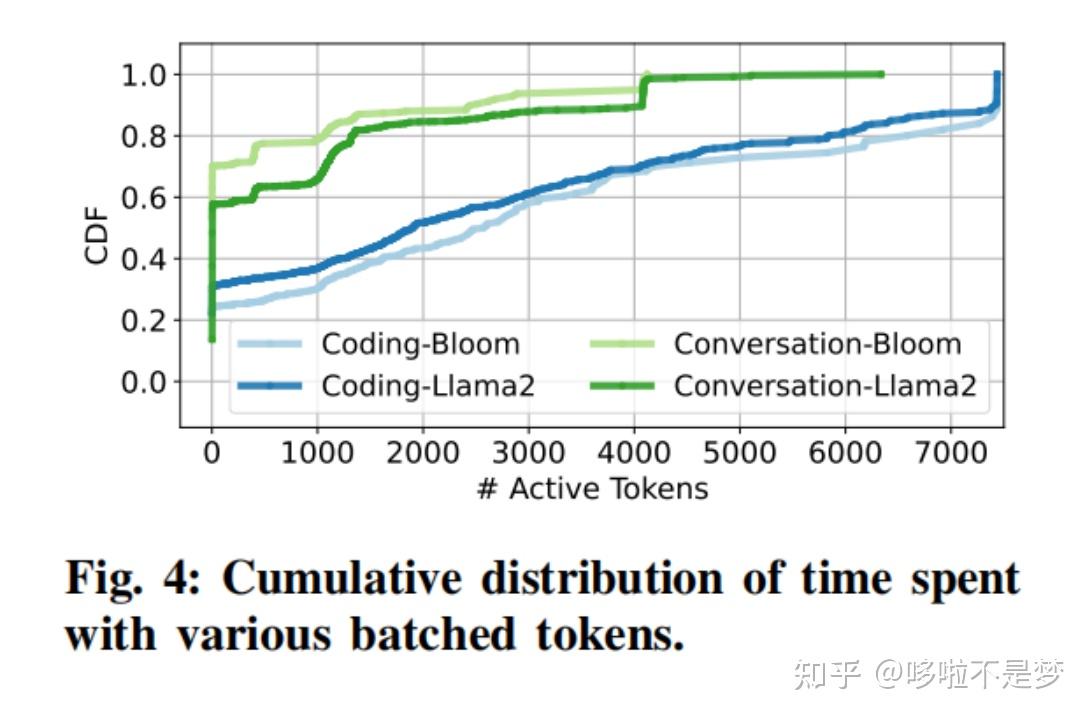
(a)是以Request为级别的Batching方法,当有多个Request来了之后,可以按照时间顺序开始执行,一旦开始执行将完整执行Prefill和Decode阶段,只有全部执行完才能开始下一个Request。比如图(a)中Request 1和2同时到达,因此一起开始执行,后续就算来了3和4也要等到1、2完整执行完才能开始。
(b)在这个方法中,一个Batch里要么单纯的做Prefill,要么单纯做Decode。因为其认为Prefill会影响到TTFT,更重要,因此一个等待的Prefill可以抢占Decode,这种做法虽然会提高TTFT,但是也会造成TBT( Time between tokens ,Decode阶段两个Token之间的时间)的尾延迟增高。
(c)中Prefill和Decode可以一起运行,这就会造成Prefill对Decode阶段产生干扰,本来可以很快执行完的Decode由于被Prefill干扰而拖慢。

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2024-10-10 16:00
发表于 2024-10-10 16:00


 提升卡
提升卡


